1. Grouping and aggregate operations over cursor
The commonest grouping & aggregate operations are counting and summation. In addition, the aggregate operation also includes seeking the maximum, minimum, and top n data. For the data aggregating operation in the cursor, you can use function cs.groups(), the aggregate functions corresponding to various aggregate operations are respectively the count/sum/max/min/topx, for example:
In A7, make statistics on the total number of orders, maximum tradeamount,
and total amount for products in each category. One thing to note is that the precision
of the double-precision data is usually not enough. In this case, decimal() is required
to convert the data to the big decimal type of computing. Regarding the
grouping and aggregate computation over cursors, all data will be traversed for
once. During traversing, the data in each row will be aggregated in its
corresponding group. Multiple aggregate values can be
computed in one traversal, and the cursor will be closed automatically once
the traversal is completed.

As can be
seen, in the adopted text data for test, each category has 50,000 records for orders. From the above example, you may find
that the data in the cursor A6 is ordered by Date, but not ordered by the field
Type. So, when using function cs.groups() to group and summarize, there is no need to have the data in the
cursor sorted. After grouping
and aggregating, result will be sorted by the grouping value. In
addition, because the function cs.groups() returns a TSeq, the result set must not exceed
the memory size when using this function to handle the grouping and
aggregating. It is not fit for the big data result set.
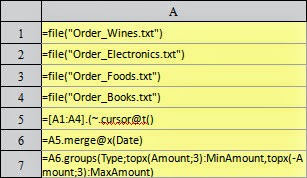
In A7, according to the computation of products of each category, the 3 orders with the lowest total prices and the other 3 orders with the highest total price can be found. Please remember to add the negative sign to the aggregate function when computing the 3 orders with the highest total price, that is, topx(-Amount:3). The result is as follows:

To aggregate all records, simply leave the grouping expression of function cs.groups blank:

The result in A7 is as follows:

This shows that the aggregating result for all records can be regarded as a
special grouping and aggregating.
2. Aggregate operations over multiple cursors
When handling the aggregate operations over multiple cursors, you can compute the result of each aggregate computation over cursor first:
In A6, group and aggregate over each file cursor respectively, and compute the daily aggregated statistics on the product data of each category:

Because the data will be sorted by group value when using the cs.groups() function to aggregate and group over the cursor, the resulting TSeq after aggregating is ordered for the Date, no matter the original data is in whatever order for each category of product. So, the result can be merged further to compute the daily order data for all products:

In A8, you will see the computation result:

Since the orders for
products of each category have been sorted by date in each data file, the
cursor can be merged, and then aggregated:

As you can see, this
method leads to the same results given above. For the cursor that is ordered
for multiple pieces of data, it would be more simple and effective to merge
first, then group and aggregate. One thing to note is
the difference between merge and merge@x:A.merge() is to merge
the members of several sequences or records of several TSeq in proper order,
and return a Sequence. The computation is completed during the operation; CS.merge@x() is to
merge the records from multiple cursors in proper order, return a cursor, and
start the real computing when fetching data from cursor. During this procedure,
the data in A
and CS must
be ordered.
3.Big data result set
In the
above section, we've learned that the data of each part can be grouped and
aggregated respectively first to have a group of ordered result TSeq, then
merge the result to get the final result of overall grouping and aggregating. With such method, we can solve the grouping and aggregating
problems related to the big data result set.
The big
data result set not only refers to the source data for computation is of huge
amount, but also the computing result. Owing to this, the computing result
cannot be read into the memory all at once. They have to be read out step by
step. For example, the telecommunication company
makes statistics on the monthly bill for each user; The B2C website collects
the statistics on the sales of each product. The statistical results based on
these data may contain more than several millions of records.

In A6, the data in each cursor can be joined one by one, instead of just being sorted by date. In A7, after the grouping and aggregating, a cursor instead of a TSeq will be returned. By doing so, the data can be retrieved step by step in A8~A11. The data are shown below:

In which,
each of A8~A10 will retrieve the statistical result
for the 100days, and A11 will retrieve the remaining data.

To execute step by step, you can view the generated temporary file in the system temporary directory once executed in A7:

In order to understand the contents of these binary files more clearly, you can retrieve the data from these files, for example:

The data in A1 and A3 are shown below:

The name of
temporary file is generated randomly. Judging from the data retrieved from some
temporary files, it can be seen that results of grouping and aggregating some
consecutive original records are stored in each temporary file, and they are
already sorted by the date. In fact, based on the number of buffered rows in
the function expression, each temporary file, except for the last one, contains
partial summary data for just 100 dates. If using groupx to generate a
cursor, and retrieving data with this cursor fetch, the data of all temporary
files will be merged in proper order.
After data are
retrieved with the cursor of temporary files or the cursor is closed, the
related temporary files will be deleted automatically.
没有评论:
发表评论