1. Merge in proper order
Many a time, data could be stored in several data tables, for example, product sales records of several categories, and employee profiles of each department. In this case, we need to merge the data from multiple data tables for combined use. For the several normal homogeneous TSeqs, you can use A.conj() or A.merge(x) to merge the records of each TSeq into RSeq for use. If the big data is used in the data table, then you can also use CS.conj@x() and CS.merge@x(x) to combine the data in each cursor of cursor sequence CS, and merge and read them out when retrieving.The data in cursor can only be traversed once, so it is impossible to sort over again after merging and retrieving all data from cursor. In view of this, the data in each cursor must be ordered in case of merging the data from multiple cursors.
Next, let's learn about the usage and difference between CS.conj@x() and CS.merge@x(x). Firstly, let’s have a look at situation about the simple union.

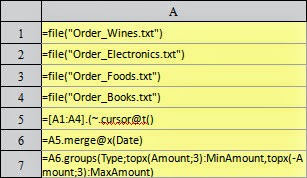
Four pieces of text data are respectively used to record the order information about wines, electrical appliances, foods, and books. In A6, the data in the four pieces of text data cursor will be united. To find out the order in which the data are retrieved, the following code retrieves 300 records each time, and suspends data retrieval once the retrieved data contains records of goods of different categories. In this case, the retrieved TSeq can be seen in B7 as follows:

As can be
learned from the result, regarding the union cursor, after all wine order data are
retrieved from the 1st text data table, start to retrieve the electrical
appliance data from the 2nd text data table. In other words, after
the simple union by using CS.conj@x() function, the records in the resulting cursor will be retrieved in
the same order as each cursor is arranged in the cursor sequence CS.


As can be
seen, the data are retrieved in a specified order of Date. Once all wine order data of January 1stis retrieved,
retrieving all electrical appliance order data of the January 1st will start.
Because retrieving data with cursor is a forward-only operation that can only
be performed from the first to the last, the order data in each cursor must be
ordered by date. After using function CS.merge@x() to merge in proper order, by comparing the current computation
expression value on each data table, the result cursor will choose from the cursors
of sequence CS
to retrieve data when retrieving records. In this
way, we can ultimately get the result arranged in the specified order. In data
retrieving, each cursor will still traverse the records in each data table for
once.
When
merging the data in multiple cursors in proper order, the multiple cursors are
simply merged into one, and the orders in which to retrieve data in each cursor
has adjusted, without increasing or decreasing any record data.

Before the
data in cursor is merged in proper order by the product sequence number, you
must ensure the data in each cursor is ordered for the product sequence number.
To do so, in A5, use function cs.sortx() to complete the sorting.
Please
note that the cursor and TSeq are sorted differently. Because there are usually
great amount of data in the cursor, they cannot be loaded into the memory all
at once for sorting. Therefore, the data retrieving is performed along with the
data sorting. The data will be saved as temporary data files
when they are accumulated to a certain amount. Once all data are retrieved and
sorted, all temporary data files will be merged in proper order, and return as
the result cursor.
In B7, the retrieved records are shown below:

As can be seen, the
ordered merging can be accomplished once the data in each cursor have been
sorted.
2.Aligned joining
When making
the statistics, sometimes, you need to consolidate the data from multiple
cursors, which is similar to joining the data from multiple tables. If the data
in cursor are required to join a normal TSeq, then you can use cs.switch().
What if the
data to join are all from the cursor? As we know, it
is usually impossible to retrieve all data in the cursor. How can we join these
data then? In esProc, you can use function join@x() to join the data from
multiple cursors. For example:

In A5~A8, perform
the aggregate operations over the products in each category, and return the
respective cursor of temporary files. In A9, the
daily sales data for products in each category will be aligned and joined by
date. From A10, retrieve the statistical results of the first 25 days, as shown
below:

Once the
cursor is aligned joined, a cursor will be returned. From which the retrieved
result is similar to the TSeq joining, and all fields are
composed of the records. Thus, when retrieving, you must note that the
joined records take more memory than those in the normal cases. In addition, since data is composed of records while not
values, please note the requirements on writing the
expression, in particular the re-joining with the result cursor, when using the
result cursor for computation.
The result
of aligned joining of cursors can also be used to inherit such as filtering or
generating, for example:

From the joined cursor,
filter out the total amount of food orders which are greater than the total
amount of wine orders, and then generate the TSeq. In A12, return the first 100 rows of results:

In using
the aligned joining with cursor, you must remember that the data in the cursor
cannot be read into and maintain in the memory during retrieving the data.
Instead, they can only be traversed for once from the first to the last. Therefore, regarding the join operation, the data in each cursor must be sorted, which is different
from processing the multi-table join for database, and quite unlike the join() for normal
TSeq. As shown in the above example, the data in A5~A8
are ordered by date, which can ensure the computation is correct when joining.
In order to
explain this problem, we create a cursor using two in-memory TSeq. Let’s have a
look:

The TSeqs in A1and A2 are shown below:

In A5, you will see the aligned joining result:

The data in
cursor is different to the normal TSeq. When looking for the New York state
corresponding to the New York city for joining, the cursor of State data has
already moved to the entry 32, and the previous
records are unfindable for later computations. So, for most cities, the
corresponding state is unfindable like this. Because the option @1 and @a are not used in
function join@x() to specify the left join or full join, only cities finding out corresponding
state are returned, and the data are quite few.
If having the city information sorted first, then you can have the normal result of joining:

In A1, the data are sorted by STATEID:

In A6, you will see the joining result: