2.Loop functions
Loop functions can compute each record of a
table sequence/record sequence, express complex loop statements with simple
function. For instance, select is
used to make query, sort to sort, id to merge repeated records, pselect to fetch sequence numbers of
eligible records and maxif to read
the maximum value from eligible records. Here the most basic ones - select function and sort function- will be illustrated. For
more information about loop functions, please refer to esProc Program: Loop Operation.
2.1 Query
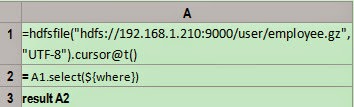
In the following cellset, query out records
whose Amount field is greater than
or equal to 20,000 and whose Date is
the month of March. As both record sequence and table sequence have the same
expression for querying data, only the latter is selected for our illustration:

The result of B1 is as follows:

Whether the computing object is a table
sequence or a record sequence, the computed result of select function will always be a record sequence, that is, the
references of records instead of the physical records.
2.2 Sort
In the following cellset, sort records in ascending
order according to SalesID field,
and for the records having the same SalesID,
sort them in descending order according to Date
field. The record sequence and table sequence have the same expression for
sorting. Here we’ll take the record sequence in B1 as an example:
The computed result is:

Whether the computing object is a table
sequence or a record sequence, the computed result of sort function will always be a record sequence. In fact, most of
the functions for table sequences and record sequences can be employed
universally unless the records are modified.
3 Aggregate function
3.1 Seek maximum
value
Seek the maximum value of Amount field. The record sequence and
table sequence in this example have the same expression, so we only take table
sequence A1 as an example:
The computed result of A2 is as follows:

Similar functions include min(minimum value), sum(summation), avg(average value), count(count),
etc.
3.2 Sum by grouping
In the following cellset, sum Amount in each group of data according
to SalesID and the month, and count
orders of each group. The record sequence and table sequence in this example
have the same expression, so we only take the table sequence A1 as an example:
The computed result of A2 is as follows:

Note: groups
function will create a new table sequence."~" in expression count(~) represents the current group. count(~) can also be written as count(ID). Besides, we don’t designate
field names of computed results in writing code, so default field names like month(Date)will appear. A colon could be used in designating field names, such
as =A1.groups(SalesID, month(Date):Month;sum(Amount),count(ID)).