It is not difficult for Java to access HDFS
through API provided by Hadoop. But to realize computations, like grouping, filtering
and sorting, on files in HDFS in Java is troublesome. esProc is a good helper
in Java’s dealing with these computations. It can execute the access to HDFS
too. With the help of esProc, Java will increase its ability in performing
structured and semi-structured data computing, like the above-mentioned
computations. Let’s look at how it works through an example.
The text file employee.gz in HDFS contains the employee data. You are required to
import the data and select the female employees who were born on and after
January 1st, 1981. The text file has been zipped with gzip in HDFS and cannot be loaded to the
memory entirely.
The data in employee.gz is as follows:
EID NAME SURNAME GENDER STATE BIRTHDAY HIREDATE DEPT SALARY
1 Rebecca Moore F California 1974-11-20 2005-03-11 R&D 7000
2 Ashley Wilson F New York 1980-07-19 2008-03-16 Finance 11000
3 Rachel Johnson F New Mexico 1970-12-17 2010-12-01 Sales 9000
4 Emily Smith F Texas 1985-03-07 2006-08-15 HR 7000
5 Ashley Smith F Texas 1975-05-13 2004-07-30 R&D 16000
6 Matthew Johnson M California 1984-07-07 2005-07-07 Sales 11000
7 Alexis Smith F Illinois 1972-08-16 2002-08-16 Sales 9000
8 Megan Wilson F California 1979-04-19 1984-04-19 Marketing 11000
9 Victoria Davis F Texas 1983-12-07 2009-12-07 HR 3000
10 Ryan Johnson M Pennsylvania 1976-03-12 2006-03-12 R&D 13000
11 Jacob Moore M Texas 1974-12-16 2004-12-16 Sales 12000
12 Jessica Davis F New York 1980-09-11 2008-09-11 Sales 7000
13 Daniel Davis M Florida 1982-05-14 2010-05-14 Finance 10000
…
Implementation approach: Call the esProc
script with Java program, import and compute the data, then return the result
to Java program in the form of ResultSet.
First, you should develop and debug program
in esProc's Integration Development Environment (IDE). The preparatory work is
to copy the core packages and the configuration packages of Hadoop to "esProc's
installation directory\esProc\lib",such ascommons-configuration-1.6.jar、commons-lang-2.4.jar、hadoop-core-1.0.4.jar(Hadoop1.0.4).
Because esProc supports analyzing and
evaluating expressions dynamically, it will enable Java to filter the data in
HDFS file as flexibly as SQL does. For example, to query the data of female
employees who were born on and after January 1st, 1981, esProc will
use an input parameter "where" as the condition, as shown in the figure below:

"where" is a string, its value is BIRTHDAY>=date(1981,1,1)
&& GENDER=="F".
The code in esProc is as follows:
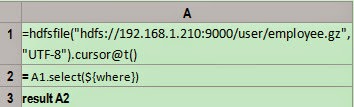
A1:Define a HDFS file object cursor
with the first row being the title and tab
being the default field separator. The zipping mode is determined by the filenameextension.
Here gzip is used. esProc also
supports other zipping modes. UTF-8
is a charset, which is a JVM charset by default.
A2:Filter the cursor according to the
condition. Here macro is used to realize analyzing the expression dynamically, in
which“where” is the input parameter. esProc will first compute the expression
surrounded by ${…}, take the computed
result as the macro string value and replace ${…} with it, then interpret and execute the code. The final code
executed in this example is =A1.select(BIRTHDAY>=date(1981,1,1)
&& GENDER=="F").
A3:Return the cursor. If the filtering condition is changed, you only need to change the
parameter "where" without modifying the code. For example, you are required to
query the data of the female employees who were born on January 1st,
1981, or of the employees in which NAME+SURNAMEis "RebeccaMoore". The code for
the value of “where” can be written as BIRTHDAY>=date(1981,1,1)
&& GENDER=="F" || NAME+SURNAME=="RebeccaMoore".
The code for calling this block of code in
Java with esProc JDBC is as follows (save the esProc program as test.dfxand put the Hadoop jars needed
by HDFS in Java's classpath):
Class.forName("com.esproc.jdbc.InternalDriver");
con= DriverManager.getConnection("jdbc:esproc:local://");
// call the program in esProc (the stored
procedure); test is the file name of dfx
st =(com.esproc.jdbc.InternalCStatement)con.prepareCall("call
test(?)");
//set the parameters
st.setObject(1," BIRTHDAY>=date(1981,1,1)
&& GENDER==\"F\" ||NAME+SURNAME==\"RebeccaMoore\"");//
the parameters are the dynamic filtering conditions
// execute esProc stored procedure
st.execute();
// get the result set, which is the eligible
set of employees
ResultSet set = st.getResultSet();
没有评论:
发表评论